| XML Class | Flash 5; Flash 6 improves performance and adds getBytesLoaded( ) and getBytesTotal( ) methods |
| DOM-based support for XML-structured data |
new XML() new XML(source)
An optional string containing well-formed XML data to be parsed into an XML object hierarchy.
An object whose properties store element attributes.
An array of references to a node's children.
The MIME content type to be transmitted to servers.
The document's DOCTYPE tag.
A reference to the first descendant of a node.
Determines whether to ignore whitespace nodes during XML parsing.
A reference to the last descendant of a node.
Status of a load( ) or sendAndLoad( ) operation.
A reference to the node after this node in the current level of the object hierarchy.
The name of the current node.
The type of the current node, either 1 (an element node) or 3 (a text node).
The value of the current node.
A reference to the immediate ancestor of a node.
A reference to the node before this node in the current level of the object hierarchy.
Error code describing the result of parsing XML source into an object hierarchy.
The document's XML declaration tag.
Add a new child node to a node.
Create a copy of a node.
Create a new element node.
Create a new text node.
The number of downloaded bytes of an external XML file.
The physical disk size of an external XML file, in bytes.
Check if a node has any descendants.
Add a sibling node before a node.
Import XML source code from an external document.
Parse a string of XML source code.
Delete a node from an object hierarchy.
Send XML source code to an external script or application.
Send XML source code to an external script or application and receive XML source in return.
Convert an XML object to a string.
Handler executed when external XML source finishes loading.
Handler executed when external XML data has been parsed into an object hierarchy.
We use objects of the XML class to manipulate the content of an XML document in an object-oriented manner and to send XML-formatted data to and from Flash. Using the methods and properties of an XML object, we can build an XML-structured document (or read an existing one) and efficiently access, change, or remove the information in that document.
|
The source code of an XML document consists primarily of a series of elements and attributes. For example, in the following XML fragment, the elements BOOK, TITLE, AUTHOR, and PUBLISHER take the same form as well-known HTML tags, and we see that the AUTHOR element supports one attribute, SALUTATION:
<BOOK> <TITLE>ActionScript for Flash MX: The Definitive Guide</TITLE> <AUTHOR SALUTATION="Mr.">Colin Moock</AUTHOR> <PUBLISHER>O'Reilly</PUBLISHER> </BOOK>
From an object-oriented perspective, the content of an XML document can be treated as a hierarchy of objects in which each element and text block becomes an object node in a flowchart-like structure.
Figure 18-7 shows our simple XML <BOOK> fragment represented conceptually as an XML object hierarchy.
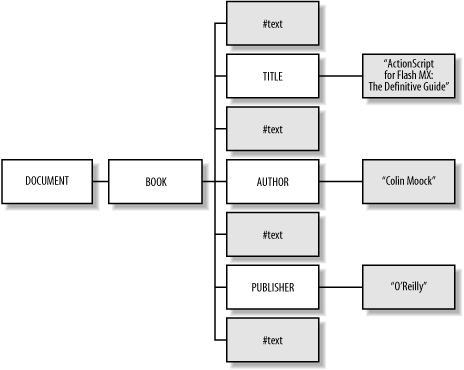
Let's consider the structure and semantics of this sample XML object hierarchy from left to right. We start with the main XML object, shown in Figure 18-7 as DOCUMENT, which is created automatically by the XML constructor and serves as the container for our XML object hierarchy.
Moving one tier to the right in the hierarchy, we come to BOOK, which is the first element in our XML source code fragment and, in this case, also the first object node under DOCUMENT. The BOOK node is the root of our XML data structure�every well-formed XML document must have an all-encompassing root element, such as BOOK, that contains every other element (the root of an XML tree has no relation to _root, which is a global property signifying the main timeline). Branches of an XML object hierarchy are added to the tree either by parsing XML source code or by invoking node-addition methods on the objects in the hierarchy.
When a node is contained by another node, the contained node is said to be a child of the containing node, which is known as the parent. In our example, BOOK is the first child of DOCUMENT, and DOCUMENT is BOOK's parent (an XML parent is unrelated to the MovieClip. _parent property).
As we move to the right in Figure 18-7, we see that BOOK has seven children, including four text nodes (shown as #text) that do not seem to be present in our original XML document. By default, each occurrence of whitespace between elements in XML source code is rendered as an object in an XML object hierarchy. If we look closely, we'll find whitespace�a carriage return and a tab character�between BOOK and TITLE in the preceding XML fragment. This whitespace is represented by a text node in Figure 18-7, which also shows similar whitespace nodes after the TITLE, AUTHOR, and PUBLISHER nodes.
BOOK's children are siblings of one another (i.e., they reside on the same level in the hierarchy). For example, we say that AUTHOR's next sibling is a text node, and AUTHOR's previous sibling is another text node. You can see how the text nodes get in our way when we're moving from sibling to sibling in a hierarchy. We can deal with these empty whitespace nodes in one of the following ways:
By manually stripping them out of our object hierarchy (see the later examples for whitespace-stripping code)
By detecting and then sidestepping them in our code (see the nextSibling and previousSibling properties for ways of moving over nodes)
By simply removing the formatting whitespace in our XML source, ensuring whitespace nodes don't appear in the first place
By setting our XML object's ignoreWhite property (available as of Flash 5.0.41.0) to true before parsing our XML source
Finally, we move to the last tier in the hierarchy, where we find that the TITLE, AUTHOR, and PUBLISHER nodes each have a single child. Each child is a text node, corresponding to the text contained by the elements TITLE, AUTHOR, and PUBLISHER. Notice that the text contained by an element in XML source code resides in a child node of that element in the corresponding object hierarchy. To access text contained by an element, we must always refer to that element's child using either firstChild.nodeValue or childNodes[0].nodeValue, which we'll consider soon.
But what of the element attributes? Where do they appear in our XML object hierarchy? You might expect AUTHOR's SALUTATION attribute to be depicted as a child node called SALUTATION. But in practice, an attribute is not considered a child of the element that defines it, but rather a property of that element. To learn how attribute properties are accessed, see the XML.attributes entry.
Let's see how to build an XML document as a hierarchy of node objects. To create a new, blank XML object, we use the XML( ) constructor:
myDocument = new XML();
We can then add nodes to our empty XML object by invoking methods such as appendChild( ), parseXML( ), and load( ) on the object. Alternatively, we can create an XML object from existing XML source in our script by invoking the XML constructor with the source argument:
myDocument = new XML(source);
For example:
myDocument = new XML('<P>hello world!</P>');
When a source argument is supplied to the XML( ) constructor, source is parsed and converted into a new object hierarchy, which is then stored in the object returned by the constructor. (In this case, the node P is assigned as myDocument's first child and the text node with the nodeValue "hello world!" is assigned as P's first child.)
Once an XML hierarchy is created and stored in an object, we can access the information in that hierarchy using the methods and properties of the XML class. For example, suppose we want to retrieve the text "hello world!" in myDocument. Thinking in object-oriented terms, we might assume that we can access the text of P as a property of myDocument, as follows: myDocument.P. In fact, that won't work; instead of referring to nodes by name, we use the XML class's built-in properties, such as firstChild and childNodes, to access nodes. For example, to access the P node, we can use:
myDocument.firstChild // Accesses P myDocument.childNodes[0] // Also accesses P
Because firstChild returns a reference to the first child node of the specified node in the hierarchy, myDocument.firstChild returns a reference to node P. However, we want the text "hello world!" contained by P, not node P itself. As we saw earlier, the text of an element node is stored within a child of that node. Therefore, we can reference the text node (i.e., the first descendant of P), like this:
myDocument.firstChild.firstChild // Accesses the text node under P
To obtain the value of a node, we use the nodeValue property. For example, we can display the value "hello world!" in the Output window using:
trace(myDocument.firstChild.firstChild.nodeValue);
Or, we can reassign the value of the text node under P using:
myDocument.firstChild.firstChild.nodeValue = "goodbye cruel world";
To perform other node-related operations, such as removing the P node altogether, adding a new node, or moving the text "hello world!" to another node, we invoke appropriate methods of the XML class. For example:
// Delete P
myDocument.firstChild.removeNode();
// Make a new element named P
newElement = myDocument.createElement("P");
// Add the new element to our document
myDocument.appendChild(newElement);
// Make a new text node to attach to P
newText = myDocument.createTextNode("XML is fun");
// Attach the new text node to P
myDocument.firstChild.appendChild(newText);
As you can see, working with XML-structured data in an object hierarchy is a mediated endeavor. We build, destroy, and manipulate the data by invoking methods on, and accessing properties of, objects. To learn the various tools available for working with XML data, explore the properties and methods of the XML class, which are listed after this entry.
In Flash Player 6, XML text should be encoded using the Unicode UTF-8, UTF-16BE, or UTF-16LE formats, which allow for the inclusion of international characters. When a file is UTF-16 encoded, it is expected to start with a byte order marker (BOM) indicating whether the encoding is big-endian or little-endian. Most text editors add the BOM automatically. When no BOM is present in a file, the encoding is assumed to be UTF-8. When in doubt, you should use UTF-8 encoding, where byte order is not an issue. For more information on UTFs and BOMs, see:
ActionScript manipulates XML data using the Document Object Model (DOM) standard published by the World Wide Web Consortium (W3C). For thorough coverage of how the DOM represents XML-structured data as an object hierarchy, consult:
For details on the language-independent specifications of the core DOM, see:
Pay particular attention to "Interface Node" under 1.2, Fundamental Interfaces.
For details on how the DOM is implemented in ECMA-262, see:
Note that all custom subclasses of the XML class that you write must invoke super( ) from their constructor function. This ensures that the methods and properties of the XML class are available to instances of the subclass.
For example:
function XMLsub (src) {
// Required! Pass raw XML source string to XML( ) constructor.
super(src);
}
XMLsub.prototype = new XML();
theDoc = new XMLsub();
theDoc.parseXML("<TEST>hello world</TEST>");
We've seen that the whitespace between any two elements in XML source code is represented by a text node in the corresponding XML object hierarchy. Prior to Flash Player 5.0.41.0, undesired whitespace nodes had to be stripped out of an XML object hierarchy manually. Stripping a particular kind of node is a common task in XML handling and serves as a good example of tree traversal (moving through every node in a hierarchy). Let's consider two different techniques for stripping whitespace nodes from a document.
In the first example, we'll use a classic FIFO (First In First Out) stack to add all the nodes in a tree to an array for processing. The stripWhitespaceTraverse( ) function seeds an array of node elements with theNode, which it receives as an argument. Then it enters a loop in which it removes the first node in the array, processes that node, and adds its children (if any) to the array. When the array has no more elements, all the descendants of theNode have been processed. During processing, any node that has no children is considered potential whitespace (because text nodes never have children). Each of these nodes is checked to see if:
It is a text node (as determined by its nodeType property).
It contains any characters above ASCII 32, which are not considered whitespace.
Any text nodes containing characters below ASCII 32 only (i.e., only whitespace) are removed:
// Strip Whitespace Using a FIFO Stack
// Function: stripWhitespaceTraverse()
// Version: 1.0.1
// Desc: Strips whitespace nodes from an XML document by traversing the tree
function stripWhitespaceTraverse (theNode) {
// Create a list of nodes to process.
var nodeList = new Array();
// Seed the list with the node passed to the function.
nodeList[0] = theNode;
// Create a local variable to track whether we've found an empty node.
var emptyNode;
// Local counter variable.
var i = 0;
// Process the passed node and its descendents until there are none left.
while (nodeList.length > 0) {
// Grab the first node on the list, and remove it from the list.
currentNode = nodeList.shift();
// Assume we're dealing with a nonempty node.
emptyNode = false;
// If this node has children...
if (currentNode.childNodes.length > 0) {
// ...add this node's children to the list of nodes to process.
nodeList = nodeList.concat(currentNode.childNodes);
} else {
// ...otherwise, this node is the end of a branch, so check if it's a
// text node...
if (currentNode.nodeType = = 3) {
// Yup, it's a text node, so check if it contains empty whitespace only.
// Assume it's only whitespace and try to prove the assumption wrong.
emptyNode = true;
for (i = 0; i < currentNode.nodeValue.length; i++) {
// A useful character is anything over 32 (space,
// tab, new line, etc. are all below 32).
if (currentNode.nodeValue.charCodeAt(i) > 32) {
emptyNode = false;
break;
}
}
}
// If no useful characters were found, delete the node
if (emptyNode) {
currentNode.removeNode();
}
}
}
}
Traditionally, the technique shown in this example is very efficient. However, in Flash Player 5, the Array.concat( ) method executes quite slowly. Hence, in Flash 5 it's quicker to strip whitespace using the technique shown in the following example. Study the comments carefully:
// Strip Whitespace Using Function Recursion
// Strips whitespace nodes from an XML document
// by passing twice through each level in the tree.
function stripWhitespaceDoublePass (theNode) {
// Loop through all the children of theNode.
for (var i = 0; i < theNode.childNodes.length; i++) {
// If the current node is a text node...
if (theNode.childNodes[i].nodeType = = 3) {
// ...check for any useful characters in the node.
var j = 0;
var emptyNode = true;
for (j = 0;j < theNode.childNodes[i].nodeValue.length; j++) {
// A useful character is anything over 32 (space, tab,
// new line, etc. are all below 32).
if (theNode.childNodes[i].nodeValue.charCodeAt(j) > 32) {
emptyNode = false;
break;
}
}
// If no useful characters were found, delete the node.
if (emptyNode) {
theNode.childNodes[i].removeNode();
}
}
}
// Now that all the whitespace nodes have been removed from theNode,
// call stripWhitespaceDoublePass( ) recursively on its remaining children.
for (var k = 0; k < theNode.childNodes.length; k++) {
stripWhitespaceDoublePass(theNode.childNodes[k]);
}
}
The XMLnode class, the XMLSocket class; Appendix E
