
Welcome to Part II. By now you should have a good idea what Python is and the general techniques for integrating Python into a Windows environment. Part II focuses on developing an advanced Windows application using Python and COM. Over the next few chapters, we'll build the core of an application, put an industry-standard Visual Basic GUI up front, demonstrate how to access it from other Office applications, show how to give the users a macro language and their own scripting capabilities, and introduce distributed processing.
In this chapter, there won't be any Windows specifics. Instead, we'll design and build a Python engine that is sophisticated enough to do some interesting and useful work; we'll then develop and integrate this further into Windows over the next few chapters. If you are new to Python, this chapter should also strengthen your understanding of object-oriented programming in Python and of manipulating basic data structures such as lists and dictionaries. Although this is just an example application, we'll touch on how you would optimize for both performance and robustness in a commercial environment.
The example application is a slimmed-down version of a set of tools developed by one of the authors over the last few years. The toolkit is intended to be a language for double-entry bookkeeping, hence the name DoubleTalk. The original intention, many years ago, was to develop a language for dealing with financial objects, in which users could express and solve a variety of financial problems. An absolute requirement is for end users to be able to work interactively and compile and run their own scripts. Python took away the need to create a whole new language; all that is needed is a class library.
We believe this general approach has great benefits in other fields. If you can build a class library to capture the essence of some problem domain and expose those classes to users in an easy-to-use environment like Python, you give them the ability to create new applications for themselves.
The core of the library is a pair of classes, Transaction and BookSet, which aim to capture the essence of a set of accounts. They enforce the rules of accounting that must be obeyed, but allow the user to perform a wide range of high-level manipulations.
Applications for the toolkit might include:
Doing real accounts
Although the class library could do this, it probably shouldn't; the place for a small company's accounts is in a commercial accounting package, and the place for a large company's accounts is in a well-managed and secure database. Nevertheless, the toolkit could be used as a layer on top of a more-secure form of storage.
Doing forecast accounts
You can write a Python simulation program to generate streams of future transactions. Such a simulation starts off with some sort of real accounts to date and adds expected future transactions. This builds a seamless picture for a business in which past and future results are evaluated on the same basis.
Matching up sets of accounts
Accountants and financial analysts often need to compare accounts. The comparison could be for different companies, different periods with varying accounting standards, or several subsidiaries needing to consolidate accounts into one coherent set of books. To do this you need interactive tools to spot gaps, close them with the right entries, establish the transformations, and write cleanup scripts.
Data laundering
You can acquire data from various databases and manual sources and write scripts to convert the data into transactions, integrating them into one overall picture of a business.
Market models
In the securities business people frequently model the behavior of financial instruments under various conditions. These instruments can be created as objects that generate transactions in response to chronology or changing economic variables. A Python simulation won't be as fast as C++, but you can have it today instead of next month. The model output includes detailed port-folio breakdowns (the balance sheet) at each point, as well as a profit-and-loss picture.
Reporting
Financial reports can be complex; they involve a lot of tables with numbers. But there are also things that must add up and rules the numbers must obey. These constraints derive from the double-entry accounting model, and reports are far easier to design if you start with a coherent data model.
Why use Python? Quite simply, because all these tasks vary slightly from company to company and from situation to situation. Rather than a monolithic application, what you need is a basic set of tools for dealing with financial objects that ensure the rules are respected and a macro language to let you customize their behavior.
We'll make this as quick as possible. There are two concepts to grasp: transactions and the chart of accounts.
The double-entry system of accounting dates back over 400 years, to an Italian named Fra. Luca Pacioli (who recently had a PC accounting package named after him). The key idea was to keep track of where money comes from and where it goes. Double-entry must rate as one of the most powerful notations ever, the business equivalent of Newton's achievements in physics. What follows is a formal notation and set of rules to encapsulate double-entry. As with physics, it's best just to work through a few examples rather than analyze the concepts too early.
A transaction is a financial event. It occurs at a certain point in time, affects two or more accounts, and the effect of those accounts sums to zero. The use of the term transaction in the database world was borrowed from accountants, who got there first by a few centuries. The key concept is that the whole thing has to happen at once or not at all; if only part of a transaction takes place, your system goes out of whack. Conceptually you can lay one out on the page like the following table.
|
A set of accounts (or BookSet) is basically a list of such transactions. An account is a way of categorizing money, but it has no precise economic meaning; fortunately, it soon becomes obvious what an account means in practice.
Here's what happens when you go out and buy something for cash.
|
By convention, increases in cash are positive, and decreases are negative. Thus, accounts for tracking expenditure like the previous one for Publications, are usually positive, and Share Capital (from the first example) has to be negative. The nonintuitive part is that accounts for classifying income have to be negative, and so does profit, which is income minus expenditure. It could as easily have been the other way around, but the decision was made centuries ago.
Cleaning this process up for the shareholders and managers should be a function of the reporting layer of the system, which aims to hide the complexity of these negative numbers. Only the programmer or database designer really needs to grasp them.
The ancients were not so happy with negative numbers and used the left and right sides of a sheet of paper, naming them debit and credit, which are plus and minus in our system. Accountants just knew that cash went on the left and income went on the right, and nobody saw a minus sign. Most people expect it to be the other way around, but the banks have been fooling you by using their viewpoint on statements and not the customer's; when your bank statement says "CR" in small letters, it means the bank is in credit: they owe you money. We programmers should be perfectly happy with a minus sign and a list of numbers, so we'll use the raw data.
It's worth noting that the phrase double-entry bookkeeping itself is slightly out of date. The old paper procedures involved two entries, but with the addition of sales taxes, many real-world transactions have three entries, and others have many entries. So multiple-entry would be a better name. If a business sells three items in the United Kingdom you want to classify separately and where sales tax is 17.5%, the sales transaction needs five entries that look like the following table.
|
Unfortunately, accountants generally are not database designers, and arguments rage in theoretical texts over the proper way to deconstruct this into pairs of entries. We won't worry about it; we've got a simple master-detail view and a constraint that the right column sums to zero, and that's all there is to it.
The second concept to grasp is that of the chart of accounts, or as we call it, the tree of accounts. There is an almost universal consensus on what standard accounts should be called and how they relate to each other. This is a large part of what is known as Generally Accepted Accounting Practice or GAAP. If you have ever struggled with rules such as assets = liabilities + capital, relax: we deal with that in the next few minutes. Every company's balance sheet is just a tree, and (with the arrival of Windows 95) almost everyone in the world knows what tree views look like, as shown in Figure 6-1..
 |
||||
| Figure 6-1. The outermost layers of a balance sheet, as a tree |
||||
Figure 6-1 shows a tree view of a company's account structure. The balance sheet has two sections, Net Assets and Capital, both of which necessarily have equal size and opposite signs.* Net Assets are what the company is worth on paper and include Assets, which have a plus sign, and Liabilities, which have a negative sign.
| * Some companies cut the cake differently, displaying Assets as the top half of the balance sheet, and Liabilities and Capital together on the bottom half. If you are interested in the book value of the company, the way we have done it brings the right numbers to the top. It won't affect our data structures either way. |
The totals on the right are inclusive balances showing everything in the tree below that point; ignore them for now.
If you investigate further (see Figure 6-2), you'll see that Assets are made up of cash, tangible assets a company owns (like computers), and money owed by others. Similarly, Liabilities includes overdrafts, money owed to creditors, and longterm loans. Capital, which has to match Net Assets, is made up of what you started with (your capital) and what you have made or lost since (Profit/Loss). Profit/Loss is simply income minus expenditure.
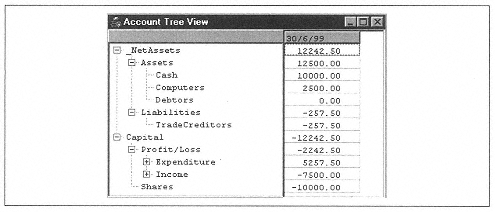 |
||||
| Figure 6-2. A simple tree of accounts |
||||
Naturally, Income and Expenditure can be divided into further specific categories, as can just about any of the accounts. But this is the simplest, reasonably complete picture of an accounting system.
Figure 6-2 is essentially correct but a bit too simple for the real world. What follows presents more realistic data, so feel free to skip to the next section if it doesn't interest you.
One of the main reasons companies have to publish accounts is to tell the world how safe they are to do business with. There are two definitions of insolvency. If a company's net assets go below zero, it's insolvent. However, an important consideration for managers, suppliers, and shareholders is whether the company has enough cash to meet its short-term obligations. If a company doesn't appear able to meet its short-term obligations, it can also be ruled insolvent. In the United Kingdom, there are titled aristocrats who own huge, historic estates they are not allowed to sell or modify for heritage reasons, and they can't possibly meet the running costs. These people have positive net assets, but they are insolvent by the second criterion. Company accounts have to handle these possibilities. We there-
fore introduce a distinction between current assets (cash, or things that should turn into cash within a year, like stock and debtors) and fixed assets (things with longer term value, like your factory). We then regroup things to get a single total of net current assets (NCA), a key indication of the short-term health of a business.
Figure 6-3 shows a simple business from two viewpoints. The left side displays six transactions occurring in date order; the right, a tree view at a point in time following the six transactions, with inclusive totals at each level. This is the tree structure we will use in examples from now on. You may find it interesting to trace how the totals were worked out.
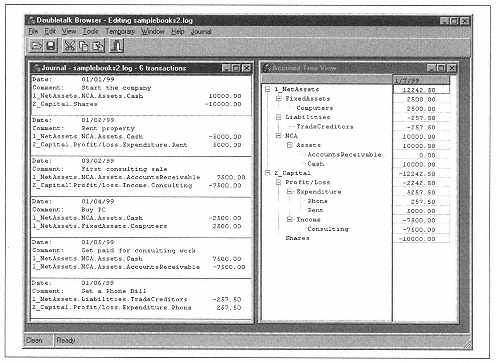 |
||||
| Figure 6-3. A set of books showing Journal and Tree Views |
||||
In the real world, category names differ from country to country, and there are many more sublevels and exceptions to deal with. But the chart of accounts is still a tree and broadly follows that pattern.
A large number of accounting systems don't actually use a tree structure. They have a flat list of numbered accounts with hardcoded rules defining which numeric ranges are assets, liabilities, income, and expenditure. This can lead to complex reporting problems, when the accounts system doesn't quite match the desired grouping for a particular kind of report. We're going to sidestep all that.
The data structures we need, then, must capture the following features:
• A transaction affects a number of accounts, but must sum to zero.
• The accounts must be arranged in a tree.
Our design goal is a general-purpose toolkit that allows you to formulate and solve financial problems in Python. To create the toolkit, we will build classes to represent common financial objects. All the code is available for downloading, so we show only selected excerpts; we do, however, list the main functions our class library makes available, for use in later chapters.
First of all, let's look at a few utilities. If you are fluent in Python, the code will be straightforward and not particularly interesting; but please skim through it anyway to grasp the business logic. If you are new to Python, this chapter should help consolidate your understanding of the language.
Python uses the Unix time system, which measures seconds since midnight on January 1, 1970 (which is when urban legend says the first Unix system booted up). The latest time possible in the system is sometime on January 19, 2038. We don't want to be tied to this system forever and will therefore express input and output in calendar units, hiding the actual implementation. The dates.py module defines a few helper constants and functions.
EARLY is defined as the earliest date possible on your system or at least earlier than any transactions you will enter. LATE is an arbitrary date later than any transaction you will enter. The functions asc2sec (aDateString) and sec2asc (aTime) convert between a string representation such as 31-Dec-1998 and seconds. Be aware that the Python time module exposes functions to do the same thing, in a slightly wordy manner, but with more options. There is also a package available called mxDateTime that offers a wider range of date utilities and functions and is worth considering for a commercial application.
The function later() works with the constants YEARS, MONTHS, WEEKS, DAYS, HOURS, MINUTES, and SECONDS to let you do calendar math easily. The following console session should clarify these:
>>> from dates import *
>>> sec2asc(EARLY), sec2asc(LATE)
('1-Jan-1970', '19-Jan-2038')
>>> endAugust = asc2sec('31-Aug-1999')
>>> billingDate = later(endAugust, 5, DAYS)
>>> sec2asc(billingDate)
'5-Sep-1999'
>>> paymentDate = later(billingDate, 2, MONTHS)
>>> sec2asc(paymentDate)
'5-Nov-1999'
>>>
Now we examine a couple of helper data structures that will come in handy later. These can be found in the module datastruct.py. A Set holds only one copy of each item; we'll use it to find the unique elements in a big list quickly. A NumDict categorizes numbers. Here's the usage:
>>> import datastruct
>>> myset = datastruct.Set()
>>> myset.add('Spam')
>>> myset.add('Eggs')
>>> myset.add('Spam')
>>> myset.contains('beer')
0
>>> myset.elements() # returned in alpha order
['Eggs', 'Spam']
>>> sales = datastruct.NumDict()
>>> sales['North'] = 100 # direct assignment, like a dictionary
>>> sales.inc('North',50) # increment it
>>> sales.inc('East', 130)
>>> sales['East']
130
>>> sales.items()
[('East', 130), ('North', 150)]
>>> sales['South'] # returned in alpha order
0
>>>
Both structures are built on top of Python dictionaries and are extremely efficient with large amounts of data. NumDict is particularly useful as we will spend a lot of time categorizing numeric data.
Now to see how these are defined. Here is the module datastruct.py:
# datastruct.py - some generic data structures
# see the Language Reference under 3.3, Special Method Names
class Set:
"minimal implementation to help clarity of code elsewhere"
def __init__(self):
self.data = {}
def contains(self, element):
return self.data.has_key(element)
def add(self, element):
self.data[element] = 1
def elements(self):
keys = self.data.keys()
keys.sort()
return keys
class NumDict:
"Dictionary to categorize numbers."
def __init__(self, input = None):
self.data = {}
if input is not None:
for item in input:
(category, value) = item
self.inc(category, value)
def __getitem__(self, key):
return self.data.get(key,0)
def __setitem__(self, key, value):
self.data[key] = value
def inc(self, key, value):
self.data[key] = self.data.get(key, 0) + value
def items(self):
it = self.data.items()
it.sort()
return it
def clear(self):
self.data.clear()
These data structures introduce some of Python's Magic Methods such as __getitem__(self, key). Magic Methods allow user-defined classes to respond to just about every operator Python provides. You can think of the most compact syntax you want for users of your class, and then implement it with Magic Methods. They are fully documented in the Python reference manual, Section 3.3, which is part of the standard distribution.
Now it's time to design a core object model. The module transac.py defines a Transaction class that captures the key notions we covered earlier. It also goes somewhat further; we've used Magic Methods to define a basic algebra of accounting. The class construction is straightforward. However, first we need to mention three design issues. Since this is a contrived application, we've gone for simple solutions that are good enough for our needs; for a proper accounting system, the solutions would be different.
• The first issue is how to represent the tree structure behind a company's accounts. After several years of experimenting with different designs, it's clear that simple strings do the job nicely. Thus a cash account can be represented with a string like MyCo.Assets.NCA.CurAss.Cash.MyWallet. This reduces lots of complex tree operations to simple string functions; finding the sum of all cash accounts becomes trivial. It should of course be hidden in the user interface to save end users from typing, but it clarifies the data structure.
• The second issue is how to keep the balance sheet in the right order as shown in Figure 6-3. You'll see that the accounts were named in alphabetical order at every level; we cheated and used 1_NetAssets and 2_Capital at the top level to force an alphabetical order. This hack keeps our tree in the conventional balance sheet order without needing any extra sort fields. The display account names used in reports (or indeed a GUI) could easily be looked up in a dictionary.
• The final design issue is whether to have a separate class instance for every single transaction, or to go for a lower-level (and faster) implementation involving nested lists and tuples, since indexing into a list is faster than accessing a class attribute. For this book we've opted for a slower but more readable implementation, and a recent upgrade from 75 to 266 MHz largely covers up the loss. We discuss options for optimizing later on.
Let's take a quick tour of how to construct and work with transactions:
>>> import transac
>>> T1 = transac.Transaction()
>>> T1.date = asc2sec('1/1/1999')
>>> T1.comment = 'Start the company'
>>> T1.addLine('MyCo.Assets.NCA.CurAss.Cash', 10000)
>>> T1.addLine('MyCo.Capital.Shares', -10000)
>>> T1.validate()
>>> T1.display() # print to standard output
Date: 1-Jan-1999
Comment: Start the company
MyCo.Assets.NCA.CurAss.Cash 10000.000000
MyCo.Capital.Shares -10000.000000
>>> T2 = transac.Transaction()
>>> T2.date = asc2sec('5-Jan-1999') # four days later…
>>> T2.comment = 'Loan from Grandma'
>>> T2.addLine('MyCo.Assets.NCA.CurAss.Cash', 15000)
>>> T2.addLastLine('MyCo.Assets.OtherLia.Loans') # addLastLine rounds\
>>> # off the final line for you
>>> T2.display()
Date: 5-Jan-1999
Comment: Loan from Grandma
MyCo.Assets.NCA.CurAss.Cash 15000.000000
MyCo.Assets.OtherLia.Loans -15000.000000
The validate() method checks if a transaction balances and raises an error if it doesn't. Later on we'll show how to ensure this is called.
Transaction objects are atomic packets of data; they don't do a lot by themselves and get interesting only in large numbers. However, they can display themselves, convert themselves to and from other formats such as blocks of text, and most important, they support some mathematical operations:
>>> T3 = T1 + T2 # we can add them together
>>> T3.display()
Date: 5-Jan-1999
Comment: <derived transaction>
MyCo.Assets.NCA.CurAss.Cash 25000.00000
MyCo.Assets.OtherLia.Loans -15000.000000
MyCo.Capital.Shares -10000.000000
>>> T4 = T1 * 1.2
>>> T4.display()
Date: 1-Jan-1999
Comment: <New Transaction>
MyCo.Assets.NCA.CurAss.Cash 12000.000000
MyCo.Capital.Shares -12000.000000
>>>
These operations make it simple to express, for example, the combined effects of a complex multistage deal or to model sales growing by 10% per month. The full API supported by Transaction objects is as follows:
def __init__(self):
Creates Transactions with the current time and no lines.
__cmp__(self, other)
Sorts Transactions according to date.
__str__(self)
Returns a printable description suitable for inclusion in, e.g., a list box.
getDateString(self)
Returns its date as a string formatted as ''12-Aug-1999 18:55:42.''
SetDateString(self, aDateString)
Allows date to be set from a text string as well as directly.
isEqual (self, other)
Returns true if the Transactions agree to the nearest second and 1/100 of a currency unit (even if comments differ).
addLine(self, account, amount, dict=None)
Lets you build transactions up a line at a time.
addLastLine(self, account, dict=None)
Saves you doing the math. The amount for the last line is worked out for you to ensure the transaction balances.
validate(self, autocorrect=0)
By default, raises an exception if the transaction isn't zero. If autocorrect is set to zero, it silently adds an entry for the magic account (uncategorized) to round it off. This might be useful in a huge import, and the extra account shows up on all your reports.
renameAccount (self, oldAcct, newAcct)
Renames accounts, or the first part of any accounts, within the transaction, thereby allowing you to restructure the tree of accounts.
Compact(self)
If there are several lines, e.g., for Cash, compacts them into one total.
effectOn(self, targetAccount)
Tells you the effect the transaction has on the target account.
__add__(self, other), __neg__(self), __mul__(self, scalar), __div__ (self, scalar)
Implements basic transaction algebra.
flows(self, fromAccount)
For analyzing financial flows: tells you how much money flowed into (or out of, if negative) the transaction from the given account.
display(self)
Prints a readable representation containing all the lines on standard output.
asTuple(self)
Returns a compact representation as a Python tuple, useful sometimes for portability and speed, as we will see later on. The module defines a function tranFromTuple(aTuple) that converts these back to Transaction class instances.
asString(self)
Returns a multiline string for use in displaying or saving to text files. The module defines a function tranFromString (aChunk) to help parse transactions in text files, although slight rounding errors can become a problem with text storage and prevent perfect round trips.
asDicts(self)
Returns a set of dictionaries holding data for multidimensional analysis.
magnitude(self)
Returns a number indicating the rough size of the transaction, for display in graphical views to help users find transactions. The meaning is somewhat undefined for complex multiline transactions!
Finally, the transac module defines a function transfer (date, comment, debitAccount, creditAccount, amount) that lets you create a transaction rapidly with just two lines.
The next step is to represent a set of books. Many accounting systems grew up with programmers and analysts trying to model the paper processes of old accounting systems, with complex posting and validation rules. Our representation turns out to be nothing more than a list of transactions in date order. Many of the common financial reports can be extracted with some simple loops through this list. In database parlance, we have normalized our design, and will now define lots of views on top of it to get the data the users want. By storing transactions and only transactions, rather than allowing the line items to exist separately in some other kind of database, it's easy to ensure that the whole system obeys the fundamental rule of summing to zero as we manipulate the data.
The BookSet class now captures the logical structure of a general set of books. We also give it the ability to load and save its data, add, edit, and delete transactions, and display common views of the data.
The examples at the web site http://starship.python.net/crew/mhammond/ppw32/ include a script, demodata1.py, that generates a BookSet with 1,000 transactions and saves it to a file for future use. This test set of data is constant and can be used for volume testing and optimization. It shows a two-year forecast business model for a small consulting company called Pythonics Ltd. which, after a shaky start, achieves superior productivity and wealth through Python.
As before, we kick off with a quick demo of some of BookSet's capabilities. We adopt the convention that methods beginning with get retrieve data, usually in the form of a list of strings or tuples, and methods beginning with list print that data to the console:
>>> bs = demodata1.getData()
>>> bs[0].display()
Date: 1-Jan-1999
Comment: Initial investment
MyCo.Assets.NCA.CurAss.Cash 10000.000000
MyCo.Capital.Shares -10000.000000
>>> bs.listAccountDetails('MyCo.Assets.OtherLia.BankLoan')
Details of account MyCo.Assets.OtherLia.BankLoan
------------------ ------------------------------
37 1-Feb-1999 Loan drawdown -10000.00 -10000.00
72 1-Mar-1999 Loan repayment 378.12 -9621.88
113 1-Apr-1999 Loan repayment 381.27 -9240.61
149 1-May-1999 Loan repayment 384.45 -8856.16
<<lines omitted>>
993 1-Jan-2001 Loan repayment 453.86 -457.50
998 1-Feb-2001 Final loan repayment 457.50 0.00
>>> endOfYear2 = asc2sec('31-Dec-2000')
>>> bs.getAccountBalance('MyCo.Capital.PL', endOfYear2) # are we in profit yet?
-258416.088
>>> # Yes, rolling in it (remember, cash is positive, profits and income are
>>> # negative)
>>> Q1, Q2 = asc2sec('31-Mar-2000'), asc2sec('30-Jun-2000')
>>> bs.getAccountActivity('MyCo.Capital.PL.Expenses', Q1, Q2)
69961.19
>>>
All these queries are implemented as simple loops over the transactions in the BookSet. For example, to get the previous account details, we implement an internal function called getAccountDetails() as follows:
def getAccountDetails(self, match):
from string import find # import into local namespace, a bit faster
runtot = 0
tranNo = 0
results = []
for tran in self.__journal:
dateStr = sec2asc(tran.date)
comment = tran.comment
for (account, delta, etc) in tran.lines:
if find(account, match) <> -1:
runtot = runtot + delta
results.append((tranNo, dateStr, comment, delta, runtot))
tranNo = tranNo + 1
return results
def listAccountDetails(self, match):
print 'Details of account', match
print '------------------' + ('-' * len(match))
for row in self.getAccountDetails(match):
print '%5d %-12s %40s %10.2f %10.2f' % row
Note line 6, for tran in self.__journal. The __ convention provides private attributes; these attributes can be referenced by name only inside the class, not by external users of the class. This is a good way to hide information.
It's worth noting the way transactions are added. They must be stored internally in date order. To ensure this, use a modified binary insertion routine lifted from the Python library module insort.py. You first validate the transaction, and then do a quick check to see if it's the first transaction in the BookSet or if it's dated the same or later than the last one, and put it at the end. Loading from a file that's already in date order is fast and saves searching. Otherwise, you should do a binary search. Inserting a transaction in a 1000-transaction journal takes no more than eight comparisons:
def add(self, tran):
# this could be optimized by putting the
# length=0 case in an exception handler
tran.validate()
if len(self.__journal) == 0:
self.__journal.append(tran)
else:
# quick check if it's the last - might happen
# very often when loading from a file
if cmp(tran, self.__journal[-1]) >= 0:
self.__journal.append(tran)
else:
self._insertInOrder(tran)
def_insertInOrder(self, tran):
# copied from Python library - binary
# insertion routine
lo = 0
hi = len(self.__journal)
while lo < hi:
mid = (lo + hi) / 2
if tran < self.__journal[mid]:
hi = mid
else:
lo = mid + 1
self.__journal.insert(lo, tran)
In most languages you would have to write a lot of code to save and load your data. In Python you don't.
BookSet uses one of Python's persistence tools, the cPickle module. Python has three modules that can save almost any structure to disk for you. Marshal is written in C and is the fastest, but is limited to numbers, strings, lists, dictionaries, and tuples. Pickle was written in Python and allows arbitrary objects to be stored to disk. cPickle is a recent rewrite of pickle in C, which allows high-speed storage approaching that of Marshal. Here are the BookSet methods to save and load the data:
def save(self, filename):
f = open(filename, 'wb')
cPickle.dump(self.__journal,f)
f.close()
def load(self, filename):
f = open(filename, 'r')
data = cPickle.load(f)
for tran in data:
self.add(tran)
f.close()
We did a little preparation by opening a file, but it takes only one line to save and reload all of our data. If you subsequently redesign your Transaction class, you don't need to rewrite the persistence code. Persistence is one of Python's most powerful features.
BookSet offers a lot of methods. We won't list them exhaustively—you'll see plenty later on—but here are the main families:
Editing methods
add(self, tran), remove(self, index), edit(self, index, newTran), renameAccount(seDates lf, oldAcct, newAcct, compact=1). These allow modification. edit() breaks down into a remove() followed by an add(), since the date and thus the location in the array might have changed. renameAccount() loops over the whole bookset; like the DOS rename command, it can also move things to a different part of the tree.
Storage methods
save(self, filename), saveAsText(self, filename), load(self, filename),loadFromText (self, filename) allow storage in files in either a fast native format or human-readable text. The native format is that produced by the cPickle utility discussed previously.
Query methods
getAccountDetails(self, account) gets the full history of entries in an account. getAccountList(self) returns a list of all the unique accounts in a BookSet. getAccountBalance(self, acct, date=LATE) tells you the balance of an account on a date, and getAccountActivity(self, acct, startDate=EARLY, endDate=LATE) gives the change in the account between two dates. getAllBalancesOn(self, date=LATE) returns the balances of all accounts on the given date or the closing balances if no date is given. We'll see how to extend the BookSet to let the user create custom queries in Chapter 8, Adding a Macro Language.
We've defined some basic classes that represent what is commonly known as the general ledger or nominal ledger, the core of any accounting system. Accounting systems generally build layers and modules around the general ledger to handle things like sales and purchases, cash management, payroll, and job and project tracking. In a conventional architecture, these might each be extra modules (sold separately) that add tables, editing screens, and reports. When new items are added, these modules might post entries to the general ledger as well as keep their own records. Unfortunately, this is the point at which businesses start to vary from each other: it's hard to predict in advance what facts companies need to keep track of.
Our transactions so far deal with the two dimensions of time and account. However, you may wish to store extra information in the future, such as the name of a customer or supplier, a check number for a payment, or a tax code for an invoice line; and you don't want to be limited to a predefined set of attributes.
Python has an unusual and extremely flexible (but potentially dangerous) feature that enables you to minimize the number of these extensions: any class instance can be given any attribute, regardless of its class definition. Let's look at how a transaction is initialized:
class -Transaction:
def __init__(self):
"By default, you get a zero transaction with time = now"
import time
self.date = int(time.time())
self.comment = '<New Transaction>'
self.lines = []
It has three attributes, date, comment, and lines. In most other object-oriented languages you would be limited to these. In Python there is absolutely nothing to stop you from doing the following:
>>> import doubletalk.transac
>>> t = doubletalk.transac.Transaction()
>>> t.Customer = 'HugeCo'
>>> t.InvoiceNo = 199904007
>>>
You don't need to define the attributes Customer and InvoiceNo in the class definition, which means you aren't limited. Your transactions can store any extra facts you wish. Furthermore, the cPickle module that provides the persistence capabilities will still save and load the objects.
In general, adding attributes on the fly like this is a bad design, because there is a strong chance users will overwrite attributes that are important to the functioning of the program. We can get away with it here since Transaction is essentially just a packet of data to be manipulated, and we want to keep the code short. In Chapter 13, Databases, you will see a much safer technique for doing the same thing, which preserves the friendly user-level syntax.
By adding these two facts to sales invoices and records of payments, you can generate reports showing who owes what or breaking down sales by customer. The converse also applies to invoices received and payments to suppliers. You can also imagine end users finding interesting new applications for this; you could tag transactions with the person who entered them, add cross references to check stubs, or anything else you want.
However, there are occasions when an attribute doesn't apply to the whole transaction but just to one line. Imagine you are billing a large customer for consulting work done by four of your staff, all working in different departments, and you want to track the income by department or team internally. You have only one
| ||||||||||||||||||||||||
|
transaction, but different attributes per line. To cope with this, the lines inside transactions are three-element tuples. Element three is usually None, but can be a dictionary. Later we will write queries that can loop over a BookSet and query based on these attributes. In the next example, we create a transaction with extra attributes at both the transaction and line level and split the income from a sale between two internal projects:
>>> INCOME='MyCo.Capital.PL.Income.Consulting' # save typing
>>> t = doubletalk.transac.Transaction()
>>> t.Customer = 'HugeCo'
>>> t.InvoiceNo = 199904007
>>> t.addLine(INCOME, 15000, {'Project':'P1'} )
>>> t.addLine(INCOME, 10000, {'Project':'P2'} )
>>> t.addLine('MyCo.NCA.CurrentAssets.Creditors', 25000)
>>> t.display() # shows the basics
Date: 27-Apr-1999 21:17:52
Comment: <New Transaction>
MyCo.Capital.PL.Income.Consulting 10000.000000
MyCo.Capital.PL.Income.Consulting 15000.000000
MyCo.NCA.CurrentAssets.Creditors 25000.000000
>>> from pprint import pprint
>>> pprint (t.__dict__) # look inside the object
{'Customer': 'HugeCo',
'InvoiceNo': 199904007,
'comment': '<New Transaction>',
'date': 925247872,
'lines': [('MyCo.Capital.PL.Income.Consulting', 10000, {'Project': 'P2'}),
('MyCo.Capital.PL.Income.Consulting', 15000, {'Project': 'P1'}),
('MyCo.NCA.CurrentAssets.Creditors', 25000, None)] }
>>>
Our data model still obeys all the fundamental rules of double-entry accounting but is now much more extensible: users can add their own attributes at will. This is the basis of a highly open, extensible system
In the next few chapters we'll see some examples of the class library at work. At the beginning of the chapter, we listed some application areas. Now we'll run briefly through how the toolkit supports some of these to give a feel for how it might be useful.
Imagine that you had one accounting system until the end of 1997. You switched in 1998, and there were some slight differences in the new chart of accounts that grouped things differently at a high level, in addition to merging one or two existing accounts. Not being administratively perfect, you didn't get it all set up on the first of January, and there is an annoying discrepancy at the changeover point you can't figure out. Export scripts can be written to get the data into BookSets. A dictionary can be prepared that maps account names in the old system to account names in the new one, and then both sets of data can be merged. Ad hoc queries using an interactive prompt also make it easy to see where data doesn't match.
One of the main uses of Doubletalk is building detailed cash-flow forecasts. Most cash-flow forecasts are done in Excel, but they tend to focus only on cash; building and maintaining a spreadsheet to correctly handle a full balance sheet and profit and loss is hard work in Excel, and anything less is ultimately not useful for long-term planning. It's also important to lay out your forecast using the same headings and tree structure as the actual data and to take care not to leave black holes where the past data meets the future. Large corporations have often invested a great deal in building such models of their businesses. The combination of object-oriented programming and our class library makes it easy.
The general concept is to create a hierarchy of business model objects that represent things in the business; these generate a stream of future transactions at the right time. The module demodata.py uses crude examples of this to generate a file of 1000 transactions. Here's a simple base class for this hierarchy:
class BusinessObject:
def getTransactions(self):
return []
There are a limited number of common business objects that can be modeled quite accurately. For example, a simple loan can be described by just five attributes: amount, date drawn, interest rate, and number of periods. A Loan object is initialized with these attributes and generates a stream of transactions covering the drawdown and the subsequent repayments. An IncomeItem gives rise to an invoice and a payment transaction, with a time lag. An IncomeStream creates a series of IncomeItems, perhaps with a given annual growth rate. The model usually needs changing only a little each month and represents cash flows accurately.
A more sophisticated model uses a discrete-event simulation approach, sending ticks of the clock to the business objects and allowing objects to make decisions based on the state of the accounts and to interact with each other. For example, a CorporationTax object could wake up once a year, look at the profits, and schedule in a few payments a few months ahead.
This approach is also important in the securities industry, where quantitative analysts (quants) build models of portfolios of financial instruments and see how they behave under different economic scenarios. A financial instrument can be seen as a business model object that gives rise to transactions at various points in its lifetime.
Our BookSet and Transaction classes can be thought of as classifying amounts of money by time and by account—a 2D classification. In fact, many standard financial reports follow a format of months across the top, and accounts (drawn from some level of the tree) down the left. Previously, we saw how to extend the system to add any attributes we wish. This effectively makes it a multidimensional model. Analyzing multidimensional data is a big business currently using the buzzword OLAP (online analytical processing). Furthermore, a common problem is to ensure the integrity of the double-entry while querying and selecting subsets of data. There is almost have a data warehouse in our BookSet; however, it's currently optimized for adding, editing, and deleting transactions, not for querying.
To query the BookSet, flatten the transactions into a separate list of facts per line. Taking the sales transaction earlier, you might extract something like what's in Table 6-1.
| |||||||||||||||||||||||||
This kind of fact-table structure is as easy to analyze in Python as it is in SQL. However, Python has a big advantage over the database world in that it's not tied to particular sets of facts, or column headings, beforehand. Transactions have the following method, which converts a three-line transaction to a list of three dictionaries, each with all the facts about transaction and line:
class Transaction:
# (one method of many)
def asDicts(self):
dicts = []
i = 0
for line in self.lines:
rowdict = self.__dict__.copy()
del rowdict['lines']
rowdict['account'] = line[0]
rowdict['amount'] = line[1]
if line[2]:
rowdict.update(line[2])
i = i + 1
dicts.append(rowdict)
return dicts
Running this on the example transaction gives everything you need to know:
>>> pprint(t.asDicts())
[{'Customer': 'HugeCo',
'InvoiceNo': 199904007,
'Project': 'P2',
'account': 'MyCo.Capital.PL.Income.Consulting',
'amount': 10000,
'comment': '<New Transaction>',
'date': 925247872},
{'Customer': 'HugeCo',
'InvoiceNo': 199904007,
'Project': 'P1',
'account': 'MyCo.Capital.PL.Income.Consulting',
'amount': 15000,
'comment': '<New Transaction>',
'date': 925247872},
{'Customer': 'HugeCo',
'InvoiceNo': 199904007,
'account': 'MyCo.NCA.CurrentAssets.Creditors',
'amount': 25000,
'comment': '<New Transaction>',
'date': 925247872}]
>>>
This is just a few lines away from an SQL-like query language that can pull out arbitrary queries from a BookSet, tabulating the keys it's interested in from the previous lists of dictionaries. You also have the ability to drill down from higher-level summaries of the data to the individual transactions that gave rise to them.
Many accounting systems can't do a cash-flow report. This sounds shocking, but it's true. The reason is they store the individual transaction lines, often in a separate table for each account and have lost the transaction itself. The cash flow report records where all the cash came from and where it went to, and is an important tool for managers.
To get a basic cash-flow report, you need to look at the other lines in all the transactions affecting the cash account. If you buy all your supplies with cash, this report breaks down how you spent your money. But if most sales and purchases are on account, the system produces the earth-shattering observation that most of your cash comes from other people paying your bills, and it goes to pay other peoples' bills. We'll call this the Brain-Dead Cash-Flow Analysis (BDCFA). A general ledger doesn't formally store the information needed to trace through the system and see what the bill you just paid was actually for.
This analysis is easy to do, if you tag the transactions with a customer and invoice number. Write a script to find all transactions with a given invoice number, add together the invoice and payment using the magic addition methods, and then perform a BDCFA on that. This lets you trace where cash went through a series of transactions.
In the context of a business, our toolkit could easily be (and has been) used to:
• Hold data exported from an accounts system
• Generate future data from a financial model
• Put the past and future together on the same basis
• Analyze this stream in various ways to produce the data for reports
• Dig down to extract more detail from totals in reports
• Compare this month's actual/forecast data against what we thought we would achieve at the beginning of the year
This part of the book showed how Python can easily build extensible applications that capture the essence of a business problem and leave users free to build their own solutions around the core.
As an example, we built a small class library which, while quick and dirty, is applicable to a wide range of financial problems. We hope that this has demonstrated the ease with which Python can capture abstractions and manipulate data.
We don't yet have an application program to use these classes or a way to look at the data. Over the next few chapters, we will build one around this class library.